
티스토리 뷰
평화롭게 회사생활을 하고 있던 어느날, 평소처럼 개발요청(개선) 하나가 들어왔다.
"의견남기기에 전송버튼을 누르는데 반응이 없어요"
정확히는 의견남기기에 전송 버튼을 누르고 아무 반응이 없어 사용자들은 여러번 클릭하게 되어 중복으로 데이터가 쌓이고 다른업무를 하는중에야 알림창이 뜬다는거였다.
보통 알림창은 api를 찌르고 응답이 온 뒤에 뜨기 때문에, 브라우저 개발자모드(F12)로 해당 api가 얼마 뒤에 응답을 주는지 확인하였다.
5초.. (pending)
10초.. (pending)
15초.. (pending)
응?

20초가 지나서야 정상응답이 오면서 알림창이 떴다.(가끔은 1분이 지나도 안됬다...)
에러가 뜨는건 아니니 지연되는 부분이 있겠구나.. 로그를 뒤져보니 update 쿼리에서 상당히 시간을 잡아먹는 것을 확인했다.
하지만 한가지 문제가 더 있었다.
개발, 품질 서버에서는 아주 잘돌아갔다! 그렇다는건 개발,품질에서는 재연이 안되니 운영에 바로 적용후 테스트 해보는 수 바께 없다는 뜻이다.
아... 안돼!

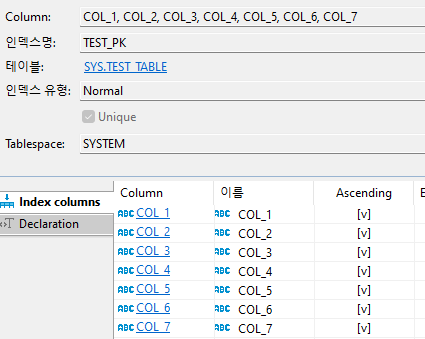
1. 테이블 정보
완벽하게 재연한 건 아니지만 핵심만 골라보자면 다중PK를 사용하고 있었고, 사용하는 컬럼들 대부분은 NOT NULL이였습니다.
CREATE TABLE test_table(
col_1 varchar2(8),
col_2 varchar2(40),
col_3 varchar2(40),
col_4 varchar2(40),
col_5 varchar2(40),
col_6 varchar2(40),
col_7 varchar2(40),
col_8 varchar2(40) NOT null,
col_9 varchar2(40) NOT null,
CONSTRAINT TEST_PK PRIMARY KEY(col_1, col_2, col_3, col_4, col_5, col_6 , col_7)
);
추가로 index를 생성한 흔적은 보이지 않았고 다중PK로 구성된 인덱스 뿐이였습니다.
해당 테이블의 데이터 총 갯수는 약 180만건, UPDATE시 0~1건만 실행됐습니다.
(나중에 찾아보니 불필요한 데이터(0건)까지 UPDATE를 하고 있었다...)
-- 180만건 더미 데이터 넣기
BEGIN
FOR i IN 1..1800000 LOOP
INSERT INTO test_table(col_1, col_2, col_3, col_4, col_5, col_6, col_7, col_8, col_9, )
VALUES(i, CONCAT('col_2-', i), CONCAT('col_3-', i), CONCAT('col_4-', i), CONCAT('col_5-', i), CONCAT('col_6-', i), CONCAT('col_7-', i), LPAD(i, 8, 'A'), LPAD(i, 8, '0'));
END LOOP;
END;
2. 문제가 됬던 쿼리문
UPDATE
test_table
SET
COL_9 = '00000010'
WHERE
COL_5 = 'col_5-10'
AND COL_3 = 'col_3-10'
AND COL_6 = 'col_6-10'
AND COL_8 = 'AAAAAA10' ;
엥...? 생각보다 단순한 쿼리였다. 컬럼 순서가 좀 이상하긴 했다.
원인 가정
1. WHERE 절에 컬럼순서가 문제
결론적으로 위와 같은 쿼리에선 컬럼의 순서가 뒤바뀐다고 문제가 되진 않습니다.
INDEX 생성시에 나열한 컬럼의 순서와 조회할 때 컬럼의 순서가 같아야 속도가 빨라진다고 생각하시는 분들이 많지만 사실상 영향이 없다고 생각하시면 됩니다.
1) 컬럼 순서에 맞춰서 조회
2) 컬럼 순서에 무관하게 조회
3) 첫 컬럼을 제외 시킨 조회
-- index 순서에 맞게 컬럼 나열
SELECT * FROM test_table WHERE COL_1 = '9999' AND COL_2 = 'col_2-9999' AND COL_3 = 'col_3-9999' AND COL_9 = '00009999';
-- 순서와 무관한 컬럼 나열
SELECT * FROM test_table WHERE COL_9 = '00009999' AND COL_2 = 'col_2-9999' AND COL_3 = 'col_3-9999' AND COL_1 = '9999';
-- index 맨앞 컬럼을 제외한 조회
SELECT * FROM test_table WHERE COL_2 = 'col_2-9999' AND COL_3 = 'col_3-9999' AND COL_9 = '00009999';
위와 같은 조회 쿼리 3개가 있습니다.
현재 INDEX는 테이블정보에 설명드린 것처럼 다중PK로 정렬된 것(COL_1 ... COL_7) 하나 뿐입니다.
1) 컬럼 순서에 맞춰서 조회
-- index 순서에 맞게 컬럼 나열
SELECT * FROM test_table WHERE COL_1 = '9999' AND COL_2 = 'col_2-9999' AND COL_3 = 'col_3-9999' AND COL_9 = '00009999';

1번의 실행계획(Execution plan)을 확인해보면 index를 타는 것을 확인 할 수 있습니다.
시간은 0.001s 걸렸습니다.
2) 컬럼 순서에 무관하게 조회
-- 순서와 무관한 컬럼 나열
SELECT * FROM test_table WHERE COL_9 = '00009999' AND COL_2 = 'col_2-9999' AND COL_3 = 'col_3-9999' AND COL_1 = '9999';

2번의 실행 계획 역시 index를 타는 것을 확인할 수 있습니다. 그럼 속도에 차이가 있을까요?
시간 역시 0.001s로 1번과 동일하다는 것을 알 수 있었습니다.
3) 첫 컬럼을 제외 시킨 조회
-- index 맨앞 컬럼을 제외한 조회
SELECT * FROM test_table WHERE COL_2 = 'col_2-9999' AND COL_3 = 'col_3-9999' AND COL_9 = '00009999';
COL_1 컬럼을 제외시켰더니 FULL SCAN을 탄다는 것을 알 수 있었습니다.
1,2번과 비교하면 Cost도 매우 높고 소요 시간 또한 0.755s로 비교적 느린 것을 확인 할 수 있었습니다.
그렇다면 "UPDATE시 SCAN에 따라 속도가 달라지는건가??" 라는 의문을 품게 됩니다.
2. FULL SCAN과 INDEX SCAN
저의 예상은 "운영서버에서 FULL SCAN을 타고 있어서 느린걸꺼야~ 인덱스 힌트 주면 빨라지겠지!" 라고 생각했지만 알아본 결과는 정반대였습니다.

개발, 품질은 "FULL SCAN", 운영은 "INDEX SKIP SCAN"을 타고 있었던 있었습니다!!
집에 돌아와 급하게 INDEX SKIP SCAN HINT를 추가하여 테스트 해보기로 했습니다.
-- FULL SCAN
UPDATE
/*+ FULL(test_table)*/
test_table
SET
COL_9 = '00000010'
WHERE
COL_5 = 'col_5-10'
AND COL_3 = 'col_3-10'
AND COL_6 = 'col_6-10'
AND COL_8 = 'AAAAAA10' ;
-- INDEX SKIP SCAN
UPDATE
/*+ INDEX_SS(test_table)*/
test_table
SET
COL_9 = '00000010'
WHERE
COL_5 = 'col_5-10'
AND COL_3 = 'col_3-10'
AND COL_6 = 'col_6-10'
AND COL_8 = 'AAAAAA10' ;
놀랍게도 FULL SCAN한 쪽이 훨씬 빨랐습니다...!
FULL SCAN의 소요시간은 1초내외, INDEX SKIP SCAN은 12초 내외였습니다.


그렇다면 개발, 품질은 왜 FULL SCAN을 타고 운영은 INDEX SKIP SCAN을 타고 있었을까요?
그것은 Cost-Based Optimizer (CBO) 관련 글에서 알 수 있었습니다. (나중에 자세히 다루겠습니다.)
CBO란 간단하게 말하자면 여러 플랜중에 제일 COST가 적은 방식을 체택하는 것입니다..
개발, 품질에서는 COST가 낮게 나온 FULL SCAN을 선택했고, 운영에서는 FULL SCAN은 92K, INDEX SKIP SCAN은 62K로 INDEX SKIP SCAN을 채택했던 것입니다!
실제로 실행시켰을 때는 FULL SCAN이 오히려 빨랐습니다.
(운영에서 INDEX SKIP SCAN은 60초 이상, FULL SCAN은 15초... 아직도 느리다)
3. INDEX 추가
집에서 테스트 했을시에는 FULL SCAN이 1초 소요로 많이 개선된 모습을 보였지만 막상 회사 운영에서 실행해보면 15초가 걸렸습니다.
전에 비해서는 많이 개선됬지만 사용자들이 여전히 불편함을 느낄 수 있을 정도였고, 더 나은 개선이 필요했습니다.
마지막 방법은 위 쿼리 WHERE절에 맞춘 INDEX를 생성이였습니다.
-- INDEX 생성
CREATE INDEX TEST_TABLE_IDX ON TEST_TABLE(COL_3,COL_5,COL_6,COL_8);

COST가 확줄었습니다.. 아 진작에 이렇게 할껄...
이제야 머리속이 정리되기 시작했습니다...
운영에서는 COST가 낮게 나온 INDEX SKIP SCAN을 하고 있었지만 TEST_PK 인덱스(의도하지 않은 혹은 잘못된 INDEX)를 타서 오히려 느려지고 있었던 것입니다.
해결 및 요약
결국 이번 문제는 잘못된 INDEX를 타고 있어 생긴 문제였습니다.
COST 크기 순으로 나열하자면 올바른 방법의 INDEX < FULL SCAN < 잘못된 방식의 INDEX 입니다.
하지만 가끔 COST가 큰 것이 막상 실행시키면 더 빠를 때도 있었습니다. (COST만 보고 판단 금지)
1) 쿼리문에 불필요한 컬럼이나 조인이 없는지 확인
2) INDEX를 타고 있는지 제대로 타고 있는지 확인
위 두가지만 기억해둬도 도움이 되겠다 생각했습니다.
더 자세히 다루고 싶지만 글이 너무 길어져서 다른글로 자세히 다뤄보겠습니다.
오타나 잘못된 정보가 있다면 댓글로 남기시면 바로 수정하겠습니다 감사합니다~

- Total
- Today
- Yesterday
- 진욱이별장자전거게스트하우스 가격
- 단양 캠핑장
- 패러글라이딩 예약
- 국토종주
- 진욱이별장자전거게스트하우스 후기
- 패러글라이딩 가격
- 국토종주 꿀팁
- 패러이야기
- 디비버
- 단양패러글라이딩 후기
- 국토종주 팁
- 진욱이별장자전거게스트하우스 예약
- 소선암캠핑장
- dbeaver
- 국토종주 필수품
- 소선암오토캠핑 리뷰
- 국토종주 숙소
- 국토종주 3박4일
- 국토종주 북한강
- 단양농협하나로마트
- 진욱이별장
- 우정캠핑
- 젠킨스
- 국토종주 후기
- Jenkins
- 단양 액티비티
- 국토종주 리뷰
- 국토종주 게스트하우스
- 진욱이별장자전거게스트하우스
- 국토종주 필수템
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 | 31 |